
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- linux
- axios
- RDS
- React
- Github Actions
- Troubleshooting
- nodejs
- python
- deploy
- MUI
- MongoDB
- github
- Express
- macbook
- springboot
- ngrok
- AWS
- fastapi
- AWS EC2
- docker
- Jenkins
- EC2
- Java
- TypeScript
- Spring
- js
- 500
- javascript
- error
- webhook
- Today
- Total
BEAT A SHOTGUN
[Python] 동시성 프로래밍으로 데이터를 더 빠르게 정렬해 Excel 로 뽑아내보자 (Feat. FastAPI, aiohttp) - 2 본문
[Python] 동시성 프로래밍으로 데이터를 더 빠르게 정렬해 Excel 로 뽑아내보자 (Feat. FastAPI, aiohttp) - 2
thovy 2023. 2. 3. 18:52[Python] 동시성 프로래밍으로 데이터를 더 빠르게 정렬해 Excel 로 뽑아내보자 (Feat. FastAPI, aiohttp)
에 이어 두번째 시간입니다.
이번 시간에는, 검색을 했을 때 바로 excel 파일로 뽑아내는 것이 아닌 버튼을 눌렀을 때 파일을 만들도록 해보겠읍니다.
그리고, naver api 가 아닌 selenium 을 활용해 진짜 데이터를 긁어보겠읍니다.
크롤링할 사이트는 비밀임. 왜냐면 robots.txt 가 안 나타남 ;; 왜지 ㅎㅎ;; 있을텐데 ㅎ;;;;
하지만 우리에게 중요한 건 단순한 크롤링이나 스크래핑이 아니라
"⚡동시성 프로그래밍으로 속도를 높인⚡ 크롤링" 이 중요한 것이기 때문에 토달면 안 됨.
일단 진행싀켜.
왜 bs4(BeautifulSoup) 을 사용하지 않나요?
내가 이번에 정보를 데려올 장소에서는 bs 로 데이터들을 데려올 수가 없다.
bs 는 정적인 페이지를 가지고 오는 것.
그래서 html 이 열리면 bs 가 가져온다. 근데 html 이 열린 뒤 js 로 페이지를 렌더링하는 동적인 페이지는 selenium 을 사용해야한다.
동적인 페이지를 bs 로 긁어보면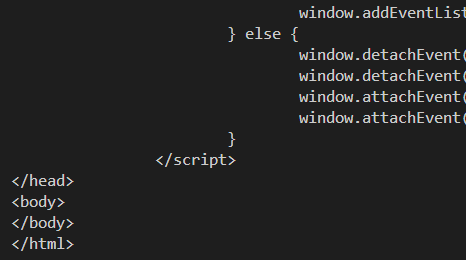
이런식으로 body 에 아무것도 나타나지 않을 수도 있다.
당황하지 말고 selenium 을 내세우자.selenium 이 가져온 페이지소스를 bs 가 가져오도록 하면 body 가 제대로 표현 될 거다. 난 이번엔 bs 안 쓸거지만.
어째됐든
시작 👊
가라, 셀리니움!!🤛
selenium 설치
pip install selenium
Chromedriver 설치
Chromedriver 설치
파일을 받아주자. 경로가 필요하지 어디 깔았는지 기억하자.
이번에는 리스트를 함수로 넣을 건데,
일반적인 for 문과 asyncio 의 반복 속도 차이를 볼 거다.
selenium 에서 가져오는 건 implicitly_wait(숫자)와 time.sleep(숫자) 를 이용해서 js 의 로딩을 기다려줘야 정확한 데이터를 가지고 올 수 있다.
만약 기다려주지 않는다면...
이렇게 데이터 중간중간에불순물이 들어간다.
간혹implicitly_wait()로도 안 되는 경우가 있으니(시작 외에는 거의 안 되더라), 물리적인 시간을 기다려주자(time.sleep())
충분히 기다려주도록하자...

그래서 데이터의 물리적인 시간을 측정하는 게 의미가 없다고 생각해서 메서드를 반복실행시키는 걸로 시간차이를 알아보려고 했다.
빠른 결론
100페이지
asyncio일반적인 for문


🙂ㅎㅎ..??
내가 비동기 프로그래밍을 제대로 이해하지 못하고 async await 와 asyncio 를 사용하고 있는 것 같다.
문제를 알아봐야겠다.
어쨌든 selenium 을 사용해 크롤링을 해보자.
그러나
🤔지금 나처럼 크롤링하는 방법이 좋은 방법은 아닌 것 같다. 일회용이지 일회용.
우리가 크롤러를 만들었던 페이지의 html 구조는 언제든지 바뀔 수 있다(대부분 그렇게 된다)🤦♂️. 페이지의 구조가 바뀌고, 크롤링할 페이지가 바뀔 때마다 일일이 find_element get_***쓰고 print 로 매번 확인해보면서 크롤링할 수는 없다.
인간은 날 때부터 단순 반복 노동을 극혐한다.
하지만 오늘은 단순반복노동할거다. ㅎ헿헤헿🤤
하지만 앞으로 이 크롤러를 어떻게 하면 다른 사이트, 다른 페이지에도 적용시킬 수 있을까 고민해보는 자세. 꼭 필요합니다. 아시겠어요?🤨
어찌됐든 만들어보자
# scraper.py
class Scraper:
def run(self, url):
return asyncio.run(self.getdriver(url))
if __name__ == "__main__":
scraper = Scraper()
# 크롤링 하고 싶은 주소를 넣어주면 됨
scraper.run( <긁고싶은페이지> )getdriver 가 없네?
getdriver 만들기
async def getdriver(self, url):
driver = webdriver.Chrome(
"C:/Users//chromedriver" # 크롬드라이버 파일이 있는 위치
)
driver.get(url)
# 크롤링할 페이지
page = 100
await self.getdata(driver, page)chromedriver를 이용해 페이지를 열고 selenium 이 움직일 수 있도록 할 거다.driver.get(url)을 하면 페이지가 열린다.getdata가 없네?
getdata 만들기
async def changedate(self, driver, page):
daylist = []
datalist = []
i = 0
while i < page:
day = ""
# 페이지에 7개 열의 데이터가 표시되더라. 그래서 0~6까지 돌면서
# 0번째 행에 있는 day(날짜데이터)를
# 1번째 행에 있는 data(가져올 데이터)를
# cell_{}_{}은 id 이다
for j in range(1, 7):
day = driver.find_element("id", "cell_{}_0".format(j)) # 날짜데이터
data = driver.find_element("id", "cell_{}_1".format(j)) # 데이터
# 긁어서 text 로 변환해준다.
# 날 것은 selenium webelement 객체가 반환되고 있다.
daylist.append(day.text)
datalist.append(data.text)
# 날짜 데이터를 바꿔주면서 다시 검색하고, 검색된 데이터를 다시 긁어줘야함.
driver.find_element("name", "input").click() # 클릭해서
driver.find_element("name", "input").clear() # 이미 있는 날짜를 지우고
driver.find_element("name", "input").send_keys("{}".format(day)) # 긁었던 데이터의 마지막 날짜를 넣고
driver.find_element("id", "btn_검색").click() # 검색버튼을 누르면 마지막 날짜부터 이 전까지 7개의 데이터가 다시 출력된다.
i += 1
# 여기에 time.sleep 을 해주지 않으면
# 데이터 중간 중간에 전 데이터의 날짜가 섞여서 들어간다.
# implicitly wait 로는 안 됨.
# 0.05 도 되는데 넉넉잡아 0.1 했다. 0.03은 안됨 데이터가 섞임.
time.sleep(0.1)
# 혹시 몰라서 마무리로 한 번 더. (안 해줘도 된다.)
time.sleep(0.1)
itemlist = defaultdict(list)
mklist = await self.mkdf(daylist, datalist, itemlist)
return mklist- 이렇게 생긴 day 조회 input
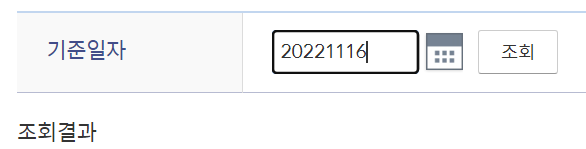
- 그러면 조회 결과가 text 로 나온다.
- 그 부분의 id 가
cell_{}_0이니find_element로 잡아서 text 로 바꾼다음 리스트에 넣어준다. - for 문 정도는 다시 함수로 뺄 수 있지 않을까 싶은데, 당장은 생각이 나지 않네요.
- 뭐 어쨌든 저 함수가 우리가 지정한 page 수 만큼 돌아갈텐데
time.sleep(0.1)로 꼭 기다려줘야한다. 앞서 서술했던 것 처럼 기다려주지 않았을 때는 데이터에 불순물이 들어갈 수 있다.
mkdf 메서드가 없네?
mkdf 만들기
async def mkdf(self, daylist, datalist, itemlist):
start = time.time()start 로 시간 측정 시작
우선
asyncio의 메서드# asyncio await asyncio.gather(*[self._map("날짜", day, itemlist) for day in daylist]) await asyncio.gather(*[self._map("데이터", data, itemlist) for data in datalist]) end = time.time() print("asyncio 소요시간", end - start)사실 딱 봐도 굳이🤨? 라고 생각될 만큼 asyncio 를 쓸 필요가 딱히 없어보인다.
날짜와 데이터를 같이 묶어 한 번에 보내면서 동시에_map으로 넣어주고 싶었는데, 생각이 안 난다.🤦♂️정말 이것보더 더 간결한 메서드로 만들 수 있을 거 같긴한데... 내 역량이 참 아쉽다. 아쉬워.😞
# 일반적인 for문
for i in range(len(datelist)):
await self._map("날짜", daylist[i], itemlist)
await self._map("데이터", datalist[i], itemlist)
end = time.time()
print("일반적인 for문 소요시간", end - start)mkdf 가 코루틴 함수기 때문에 await 를 붙여줘야한다. 붙여주지 않으면 에러가 발생함.
itemlistdf = pd.DataFrame(itemlist) itemlistdf.to_excel("crawling.xlsx") return itemlistpandas의Dataframe을 이용해서 엑셀로 내보냄. ❗openpyxl이 설치되어 있어야함.
속도차이
asynciofor
에...🙂ㅎㅎ..뭐 그렇습니다...ㅎㅎ
10배나 차이가 나네..ㅎㅎㅎ왜그런지 이해못하는 ㄴ ㅏ는 정말 동멍청이


항상
만들 때는 오 재밌겠다. 재밌다. 하고 만드는데 만들고 보면 허섭스레기같은 결과물이 나오네.
앞선 1편에서 excel 파일을 검색할 때 만들어버리지말고 버튼을 눌러 원할 때만 만들어야겠다. 생각한 것도 만들었는데 그냥 그저 그렇다. 아주 쓸만한 것도 아니고 그렇게 어려운 것도 아니고... 그냥 정말 그냥 그저 그렇다. 있으니 좋고 편한데 뭐 대단한 건 아닌... 만들 땐 재밌는데..
이번 크롤러도 js 가 렌더링되기를 물리적으로 기다려야해서 time.sleep을 거는 바람에 100페이지 600개를 가져오는데 거의 2분 3분이 걸린다. 돌아가는 chrome 페이지를 보면 깜박거리면서 열심히 렌더링하고 긁고 있음. implicitly wait 로 해결됐다면 좋으련만 그건 html 페이지가 열리면 넘어가버리는 건가봉가.
아무튼! (아무튼무새)
asyncio 를 제대로 사용하기 위해서는 뭔가 조금 더 근본적인 걸 공부해야하지 않을까 생각했다.
끝
거의 일기네 일기야 diary 를 만들어야겠어 아주
💩이다 💩
읽어보면 좋을 거 같은 것
비동기
'LEARNING' 카테고리의 다른 글
| [FastAPI] MongoDB 와 연결해 CRUD api 만들기 (0) | 2023.02.07 |
|---|---|
| [FastAPI] 가상환경에 들어가서 FastAPI 설치하기 (0) | 2023.02.05 |
| [Python] 동시성 프로래밍으로 데이터를 더 빠르게 정렬해 Excel 로 뽑아내보자 (Feat. FastAPI, aiohttp) (1) | 2023.01.29 |
| [DOCKER] Dockerfile 만들어서 로컬에서 실행해보기 - docker 첫걸음 (0) | 2022.12.27 |
| Regist MicroSoft Clarity on My Blog(tistory) (0) | 2022.10.05 |